Janus Pro
IA multimodal de código abierto para análisis y creación inteligente de imágenes
Janus Pro es un innovador sistema de inteligencia artificial multimodal de código abierto que domina tanto la interpretación como la creación visual. Este modelo unificado ofrece capacidades excepcionales de generación y análisis de imágenes con una arquitectura optimizada y licencia comercial flexible.
Janus Pro Análisis
Introducción
¿Qué es Janus Pro?
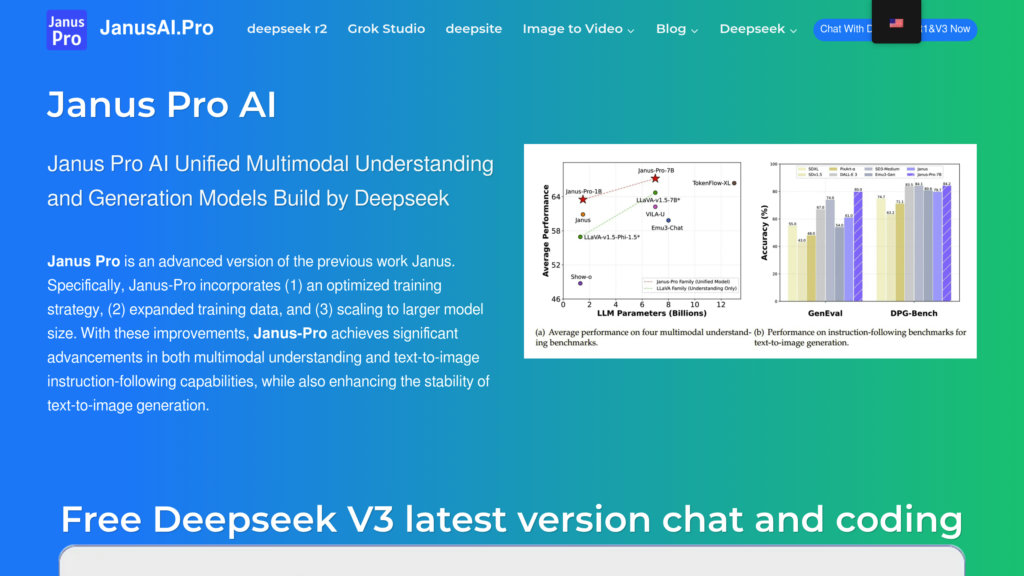
Janus Pro, desarrollado por DeepSeek, representa la vanguardia en inteligencia artificial multimodal, fusionando capacidades de interpretación y creación visual dentro de una arquitectura Transformer única. Incorpora un mecanismo de codificación visual diferenciado que optimiza independientemente los procesos de análisis y generación de imágenes, garantizando máxima adaptabilidad y exactitud. Entrenado mediante extensas colecciones de datos auténticos y sintéticos, supera a referentes del sector como DALL-E 3 en generación texto-imagen, alcanzando una calificación GenEval de 0.80 comparado con 0.67. Disponible en configuraciones de 1B y 7B parámetros bajo licencia MIT, permite implementación comercial sin limitaciones y está accesible mediante plataformas como Hugging Face y GitHub. Su diseño eficiente y escalabilidad económica lo posicionan como solución ideal para desarrolladores, investigadores y organizaciones que requieren capacidades multimodales versátiles.
Características Principales
Arquitectura Multimodal Integrada
Utiliza un framework Transformer consolidado con canales de procesamiento visual independientes para gestionar óptimamente tanto tareas de interpretación como de creación de imágenes.
Excelencia en Rendimiento
Sobrepasa a competidores destacados como DALL-E 3 y Stable Diffusion, logrando 0.80 en GenEval, con especial dominio en la traducción de instrucciones textuales a contenido visual.
Código Abierto y Comercialización Libre
Distribuido bajo licencia MIT, autoriza uso, adaptación e implementación comercial sin restricciones, con acceso completo a código y modelos en Hugging Face y GitHub.
Procesamiento Visual Avanzado
Analiza imágenes en resolución 384×384 empleando el codificador visual SigLIP-L junto con adaptadores MLP para extracción eficiente de características y transición entre tareas.
Escalabilidad Económica
La configuración ligera de 7B parámetros minimiza requerimientos computacionales y costos operativos versus alternativas propietarias, facilitando implementación extensiva.
Entrenamiento Exhaustivo y Ajuste
Capacitado mediante combinación masiva de datasets reales y sintéticos mediante proceso multi-etapa que refina estabilidad, precisión e integración multimodal.
Casos de Uso
Generación de Imágenes con IA: Produce contenido visual de alta calidad a partir de descripciones textuales para iniciativas creativas, desarrollo de prototipos y producción de material gráfico.
Interpretación y Examen Visual: Ejecuta reconocimiento avanzado de imágenes, respuesta a consultas visuales e identificación de locaciones para aplicaciones educativas y analíticas.
Reconocimiento Óptico de Caracteres: Captura texto desde imágenes con eficiencia para respaldar digitalización documental, extracción de información y flujos de trabajo automatizados.
Investigación y Desarrollo: Utiliza modelo multimodal de código abierto y personalizable para exploración académica e innovación en inteligencia artificial.
Soluciones Empresariales de IA: Implementa capacidades multimodales rentables en entornos corporativos para potenciar creación y comprensión de contenido visual.
Por favor inicia sesión para publicar un comentario
Iniciar sesión