Janus Pro
IA multimodale open source pour analyse et création d'images intelligentes
Janus Pro est un modèle d'intelligence artificielle multimodal open source révolutionnaire, maîtrisant à la fois l'analyse et la création visuelles. Avec ses performances exceptionnelles et son architecture évolutive, il redéfinit les standards en matière de traitement image-texte pour les applications professionnelles et créatives.
Janus Pro Analyse
Présentation
Présentation de Janus Pro
Janus Pro, développé par DeepSeek, représente une avancée majeure dans le domaine des intelligences artificielles multimodales. Ce système innovant fusionne capacités d'interprétation et de production d'images au sein d'une architecture Transformer harmonisée.
Son mécanisme de codage visuel distinct permet d'optimiser indépendamment les processus d'analyse et de génération d'images, garantissant une précision et une adaptabilité remarquables.
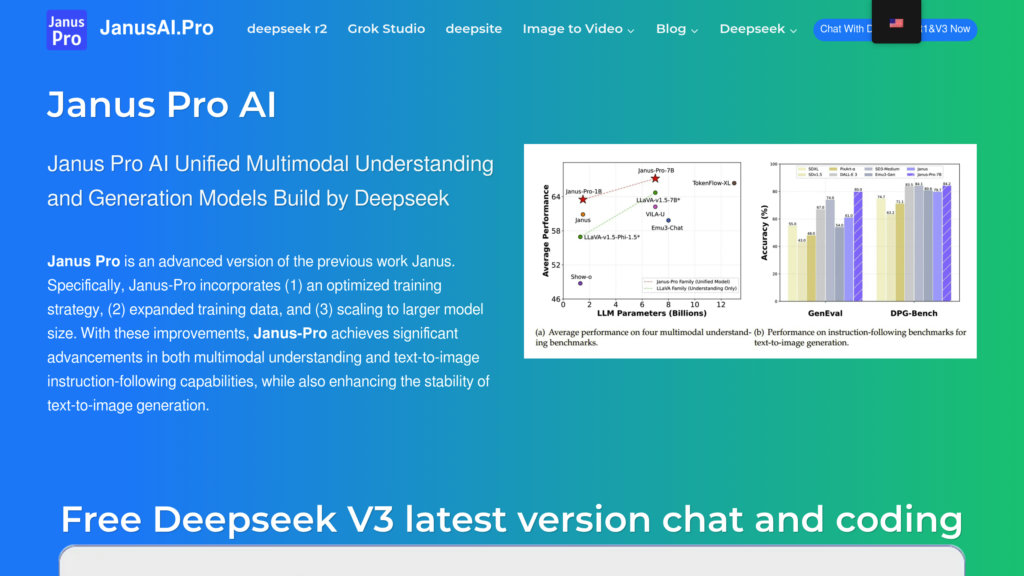
Formé sur d'immenses collections de données authentiques et artificielles, Janus Pro devance les modèles références comme DALL-E 3 dans les exercices de création image à partir de texte, obtenant un indice GenEval de 0,80 contre 0,67.
Proposé en versions 1 et 7 milliards de paramètres sous licence MIT, il autorise une exploitation commerciale sans limitations et est disponible sur des plateformes telles que Hugging Face et GitHub.
Sa conception efficiente et son extensibilité économique en font une solution parfaite pour développeurs, scientifiques et organisations recherchant une IA versatile pour applications multimodales.
Fonctionnalités principales
Architecture Multimodale Intégrée
Emploie un framework Transformer unifié avec des circuits de traitement visuel autonomes pour manager optimalement les missions d'interprétation et de production d'images.
Excellence Performantielle
Devance les principaux compétiteurs incluant DALL-E 3 et Stable Diffusion, avec un indice GenEval de 0,80, brillant particulièrement dans l'exécution de consignes associant texte et image.
Open Source et Commercialisable
Distribué sous licence MIT, permettant utilisation, adaptation et implémentation commerciale sans frais, avec accès intégral aux codes et modèles sur Hugging Face et GitHub.
Traitement d'Image Raffiné
Analyse les images en définition 384×384 via l'encodeur visuel sophistiqué SigLIP-L couplé à des adaptateurs MLP pour une extraction optimale des attributs et une transition aisée entre différentes tâches.
Extensibilité Rentable
L'agencement efficient du modèle à 7 milliards de paramètres minimise les exigences computationnelles et les dépenses comparé aux solutions propriétaires, favorisant une adoption étendue.
Apprentissage et Affinage Approfondis
Entraîné sur un vaste amalgame de jeux de données réels et synthétiques suivant un processus multi-étapes renforçant stabilité, exactitude et cohésion multimodale.
Domaines d'application
Création d'Images Assistée : Produisez des visuels haute définition à partir de descriptions textuelles pour projets artistiques, maquettes et génération de contenus visuels.
Interprétation et Examen d'Images : Mettez en œuvre reconnaissance avancée d'images, interrogation visuelle et repérage d'éléments distinctifs pour usages pédagogiques et analytiques.
Reconnaissance de Caractères : Extrayez efficacement le texte depuis des images pour numérisation documentaire, collecte d'informations et automatisation de processus.
Investigation et Progrès Technologique : Utilisez un modèle IA multimodal open source et adaptable pour recherches universitaires et innovations en intelligence artificielle.
Solutions Commerciales IA : Intégrez des fonctionnalités IA multimodales économiques dans les écosystèmes professionnels pour enrichir la production et l'analyse de contenus visuels.
Veuillez vous connecter pour publier un commentaire
Se connecter