Unreal Speech
Sintesis Suara AI Realistis & Cepat
Platform text-to-speech cerdas yang menghasilkan suara mirip manusia dengan biaya sangat rendah dan latensi ultra-rendah untuk pengembang.
Unreal Speech Analisis
Perkenalan
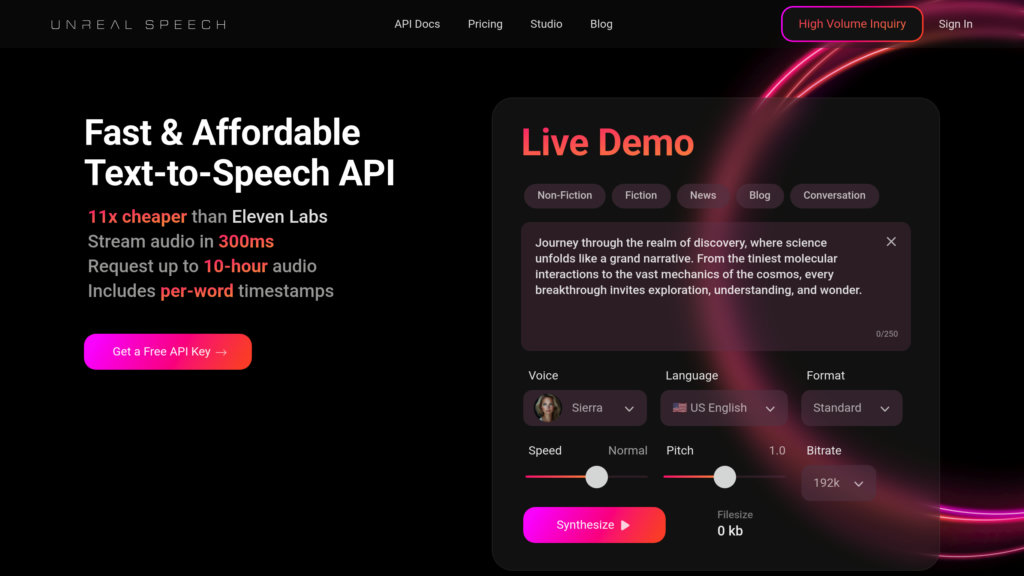
Apa itu Unreal Speech?
Unreal Speech adalah platform text-to-speech (TTS) cerdas mutakhir yang menyediakan sintesis suara mirip manusia dengan biaya sangat terjangkau. Solusi ini menggabungkan pemrosesan latensi ultra-rendah dengan jaringan saraf untuk menghasilkan output audio berkualitas tinggi secara real-time. Dibangun untuk pengalaman pengembang, platform ini menawarkan integrasi API yang mulus dan kemampuan manipulasi suara canggih, termasuk kontrol emosi, kecepatan bicara, dan modulasi nada.
Fitur Utama
- Implementasi biaya efisien dengan TTS premium hingga 11x lebih murah.
- Latensi ultra-rendah di bawah 300ms untuk generasi audio real-time.
- Portofolio 48 suara AI berbeda dalam 8 bahasa dengan berbagai karakteristik.
- Kustomisasi suara lanjutan untuk kecepatan, nada, dan ekspresi emosi.
- Integrasi berpusat pada pengembang dengan API streaming dan sintesis.
- Pemetaan audio presisi dengan timestamp per kata untuk sinkronisasi.
Kasus Penggunaan
- Optimasi konten: Mengubah konten tertulis menjadi format audio yang menarik.
- Peningkatan e-learning: Menciptakan pengalaman edukasi imersif dengan narasi AI alami.
- Solusi aksesibilitas: Mengaktifkan fungsi screen-reader untuk pengguna tunanetra.
- Dukungan otomatis: Mengintegrasikan suara realistis ke chatbot dan asisten virtual.
- Produksi audio profesional: Membuat buku audio dan konten media berkualitas tinggi.
- Sistem suara real-time: Menyebarkan sintesis suara instan untuk aplikasi live.
Pertanyaan Umum
- Apa keunggulan utama Unreal Speech? Biaya sangat rendah, suara mirip manusia, dan latensi ultra-rendah.
- Untuk siapa platform ini? Pengembang, pembuat konten, dan perusahaan yang butuh solusi TTS.
- Apakah tersedia banyak pilihan suara? Ya, tersedia 48 suara AI dalam 8 bahasa berbeda.
- Bagaimana integrasi teknisnya? Menyediakan API yang mudah diintegrasikan untuk pengembang.
Silakan masuk untuk memposting komentar
Masuk