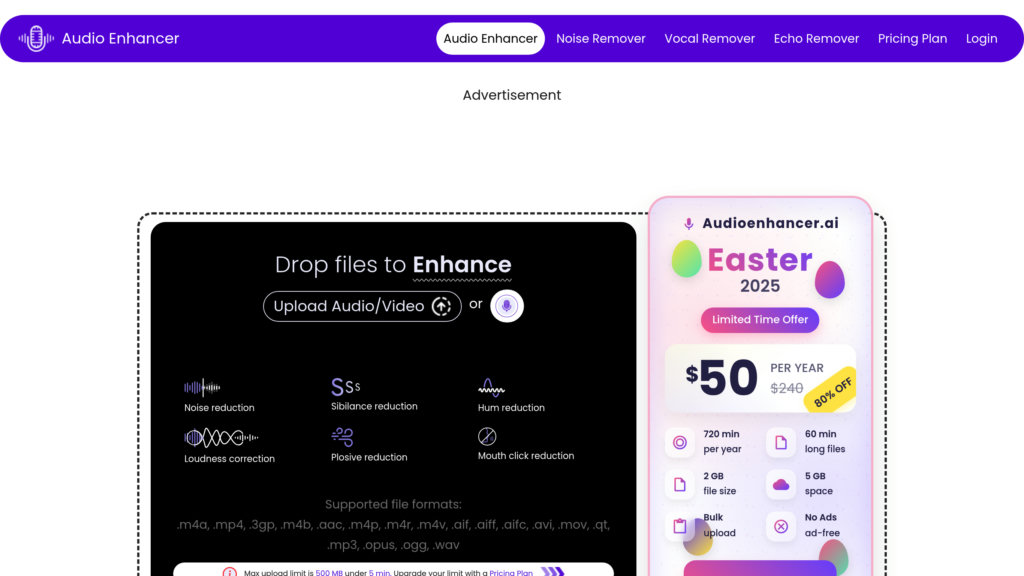

专业级远程音视频录制平台,支持本地采集录音棚级音质与4K画质,广泛用于播客、访谈和内容创作,具备AI驱动的后期处理功能。
功能亮点
- 支持双轨独立录音,确保主持人与嘉宾音频独立无干扰。
- 内置AI降噪与语音增强技术,可一键优化原始音频质量。
优势
- 提供无损音质本地录制,有效避免网络传输导致的音频劣化,保障专业制作水准。
- 集成AI剪辑工具,支持自动降噪、语音转写与多轨同步,提升后期效率。
劣势
- 免费版导出内容带有水印,高级功能需订阅,对个人创作者成本偏高。
- 界面功能丰富但学习曲线较陡,新手需要时间适应操作逻辑。
双轨本地录制保障音质纯净
AI降噪与语音增强一体化
支持中文界面与字幕输出
全球节点支持中国稳定访问




请登录后发表评论
登录