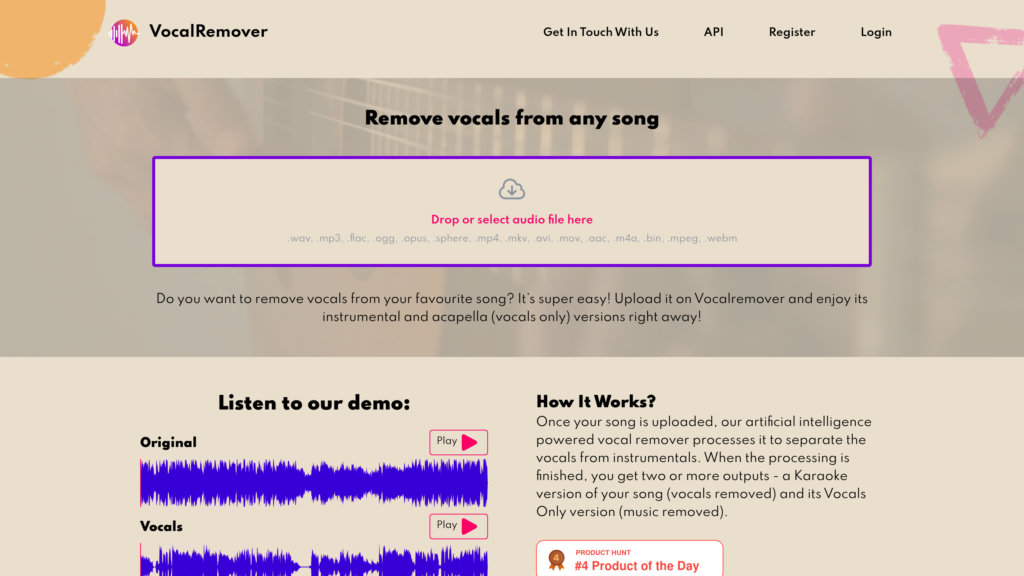

Youka是一款基于AI的智能音频处理工具,专注于将任意歌曲或YouTube视频转换为专业级卡拉OK伴奏。支持精准人声分离与歌词同步,适合音乐爱好者和内容创作者使用。
功能亮点
- 一键从YouTube提取音频并生成无损伴奏
- 支持自定义调整人声消除强度与声道平衡
优势
- 采用先进AI模型实现高精度人声与伴奏分离,输出音质清晰稳定
- 支持YouTube视频直接导入并生成卡拉OK文件,操作便捷高效
劣势
- 中文界面和本地支付支持较弱,对国内用户不够友好
- 免费版功能受限,高级功能需订阅且价格偏高
支持YouTube直连提取伴奏
人声分离精度行业领先
海外优先布局,国内访问略慢
缺少原生中文支持


请登录后发表评论
登录